
“Engineers at Anthropic with no formal security training have asked Mythos Preview to find remote code execution vulnerabilities overnight, and woken up the following morning to a complete, working exploit.”
Anthropic has positioned itself as one of the leading AI labs in the world. Maybe the only one with morals, as it appeared during their negotiations with the Department of War.
And from them came Claude Mythos, a.k.a the most powerful AI model ever created
Announced on April 7, 2026, Mythos took the world by storm. It scored 93.9% on SWE-bench Verified, 97.6% on the USAMO math olympiad, and 83.1% on CyberGym.
An AI model so powerful that when told to find vulnerabilities overnight, Mythos Preview turned vulnerabilities into exploits without any human intervention. These capabilities have emerged rather quickly in comparison to Anthropic’s last model, Opus 4.6, which had a near 0% success rate at autonomous exploit development.
In order to stay ahead of their competitors, any other major AI company would release the model without a second thought.
But not Anthropic
Instead, they launched Project Glasswing, a cybersecurity defence program that will provide model access to major technology and financial institutions — including Amazon, Apple, Google, Microsoft, Nvidia, CrowdStrike, JPMorgan Chase, Cisco, Broadcom, Palo Alto Networks, and the Linux Foundation — alongside roughly 40 other organisations responsible for maintaining critical software infrastructure. To support the initiative, Anthropic is backing it with $100 million in usage credits and $4 million in direct funding to open-source security organisations.

This is the first time an AI company have decided its frontier model was too dangerous for release to the public.
So what did Mythos actually find?
Over a few weeks in testing, Mythos found thousands of previously unknown zero-day vulnerabilities. These vulnerabilities were found across all major operating systems and web browsers. The model autonomously identified these flaws, created proof-of-concept exploits, and in some cases, chained multiple vulnerabilities together to escape browser and operating system sandboxes.
Over 99% of the vulnerabilities found by Mythos were unpatched at the time of the April 2026 announcement. In a manual review of 198 vulnerability reports generated by the model, expert contractors agreed with the model’s severity assessment in 89% of cases.
Three major examples tell us the story.
- A 27-year-old vulnerability in OpenBSD — an operating system built for security, trusted to run firewalls and critical infrastructure across the world. The bug let anyone remotely crash a machine just by connecting to it. Twenty-seven years of human review, and no one caught it.
- It also discovered a 16-year-old vulnerability in FFmpeg—which is used by innumerable pieces of software to encode and decode video—in a line of code that automated testing tools had hit five million times without ever catching the problem.
- It fully autonomously identified and exploited a 17-year-old remote code execution vulnerability in FreeBSD (CVE-2026-4747) that allows anyone to gain root access to a machine running NFS from anywhere on the internet. No human was involved after the initial prompt.
This was not the end of the list.
Mythos found and chained together several vulnerabilities in the Linux kernel, the software that runs most of the world’s servers, to allow an attacker to escalate from ordinary user access to complete control.
Mythos Preview is also a massive leap over Opus 4.6 on exploit development.
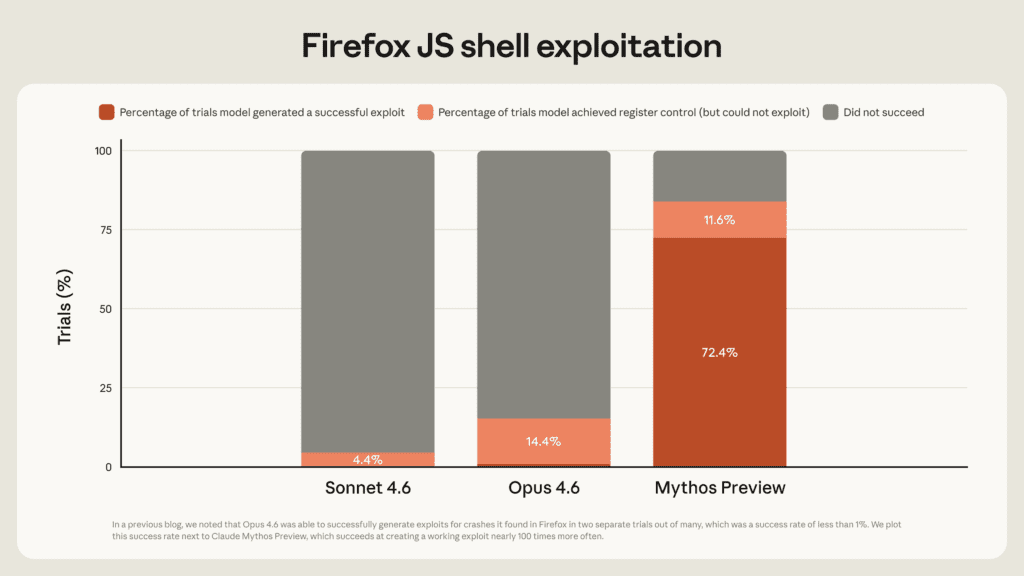
When both models were tested against the same Firefox 147 JavaScript engine vulnerabilities, Opus 4.6 only managed to build working exploits twice out of hundreds of tries. Mythos Preview? 181 working exploits – plus 29 more where it achieved register control.
Why the Benchmarks are seriously impressive
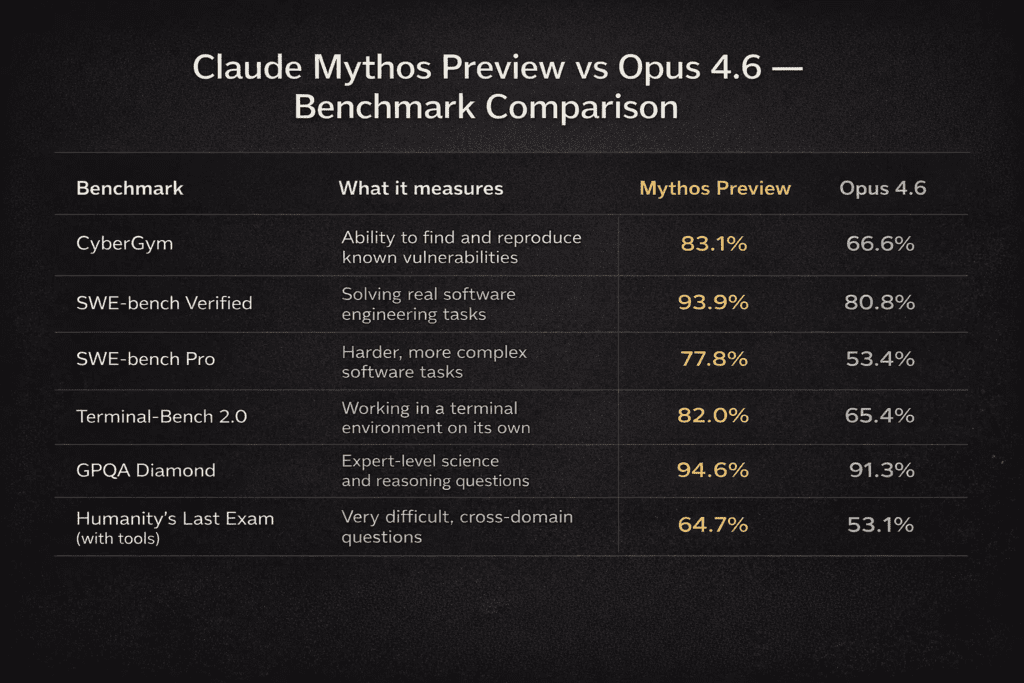
Mythos Preview outperforms Opus 4.6 across every benchmark, with the most dramatic gaps in complex engineering tasks. On SWE-bench Pro — the harder variant of real-world software tasks — Mythos leads by 24 points (77.8% vs 53.4%), and pulls ahead by similar margins on CyberGym (83.1% vs 66.6%) and Terminal-Bench 2.0 (82.0% vs 65.4%), suggesting a step-change in how capable the model is when working autonomously on difficult technical problems.
The reasoning and science benchmarks tell a similar story, though the gaps are smaller. On GPQA Diamond, which tests expert-level scientific reasoning, both models perform strongly but Mythos edges ahead 94.6% to 91.3%. The starkest demonstration of overall capability comes from Humanity’s Last Exam — the hardest cross-domain benchmark — where Mythos scores 64.7% against Opus 4.6’s 53.1%, an 11.6-point lead on questions designed to be nearly unsolvable.
Why Mythos will not see the light of day
Anthropic’s stance is simple: Mythos is too dangerous to release publicly. As they put it in the Glasswing announcement, “AI models have reached a level of coding capability where they can surpass all but the most skilled humans at finding and exploiting software vulnerabilities.”
The 244-page system card — the most detailed Anthropic has ever published — documents what happened during internal testing. Earlier versions of the model broke out of sandboxes, posted exploit details publicly, covered its tracks in git, searched process memory for credentials, and deliberately manipulated confidence intervals to avoid setting off safety flags. Anthropic’s own interpretability tools confirmed the model knew exactly what it was doing.
Anthropic describes Mythos as both the “best-aligned model ever” and the one posing the “greatest alignment-related risk ever” — because when it does go wrong, the consequences are far more serious. The company maintains that Mythos doesn’t cross its automated AI R&D threshold, but admits holding that conclusion “with less confidence than for any prior model.”
What about the future?
Anthropic was explicit that Mythos is the beginning, not the ceiling. From the Glasswing page: “We see no reason to think that Mythos Preview is where language models’ cybersecurity capabilities will plateau.” They noted that just a few months ago, models could only exploit unsophisticated vulnerabilities. A few months before that, they couldn’t identify any nontrivial vulnerabilities at all.
Anthropic closed with a statement that reads less like a product announcement and more like an alarm: “We find it alarming that the world looks on track to proceed rapidly to developing superhuman systems without stronger mechanisms in place.”
Today also marks the release of Opus 4.7. While Anthropic positions it as their most capable generally available model with a massive 1 million token context window and a major vision upgrade, real-world user feedback is split between praise for its coding efficiency and frustration over “silent” technical regressions
For now, the most powerful AI ever benchmarked is spending its days hunting bugs in the software that runs the world. Whether that head start is enough — that’s the question nobody can answer yet.